江南体育(JNsports)官网app下载 快手大模子算法工程师口试题: Sparse Attention高效优化机制详解

第1题:为什么需要优化倨傲视力机制?现在主流的高效优化标的有哪些?
口试官发问:
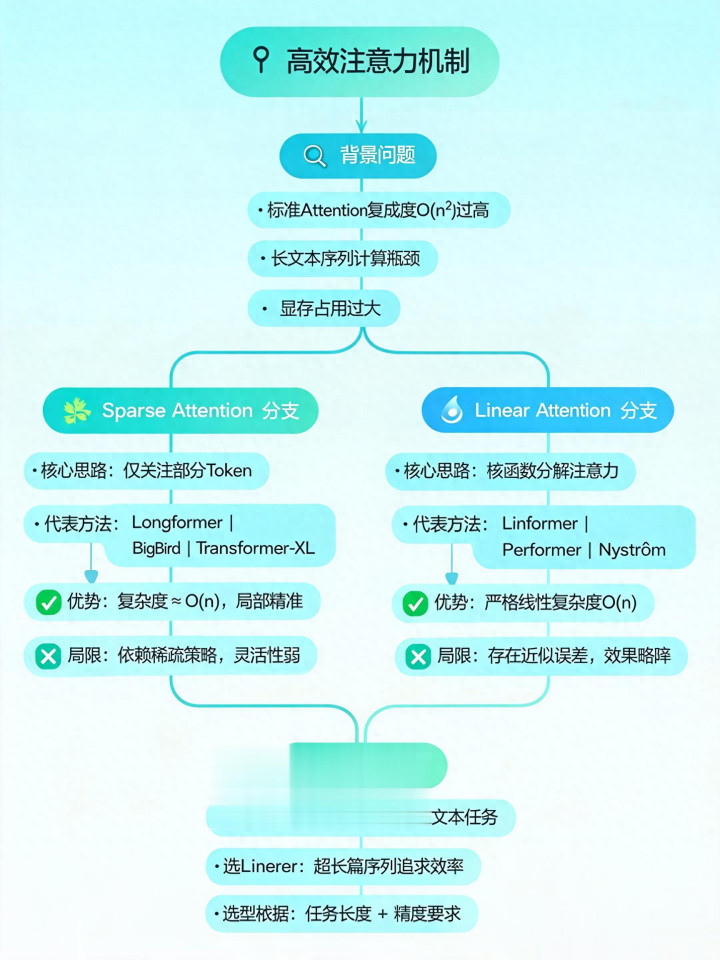
传统倨傲视力机制存在什么中枢问题?针对这个问题,现在主流的高效选藏力优化标的主要有哪两类?
必一体育中国官网入口你的回话:
传统倨傲视力应该是复杂度太高了吧,好像是和序列长度平日筹商,长序列的时候筹画量相配大。主流优化标的应该有寥落选藏力,还有线性选藏力?具体细节我记不太清了,粗略是一个减少筹画量,一个改革筹画样子?
口试官守望谜底:
传统倨傲视力的中枢问题是时代和空间复杂度均为O(n²),跟着序列长度n增长,筹画资源虚耗呈平日级飞腾,无法高效处理长文本。现在主流的两类优化标的区分是:第一类是Sparse Attention,中枢是基于“序列元素仅与部分元素筹商”的假定,通过减少不消要的筹商性筹画来镌汰复杂度;第二类是Linear Attention,中枢是期骗矩阵乘法长入律改革筹画轨则,幸免生成n×n的选藏力矩阵,将复杂度降到线性级。
第2题:Sparse Attention有哪些典型类型?各自的中枢特色是什么?
口试官发问:
Sparse Attention主要分为哪几种典型类型?每种类型的中枢设想想路和适用场景有什么区别?
你的回话:
我牢记有局部选藏力和彭胀选藏力,局部即是只看隔壁的元素,彭胀是隔几个位置看全局?还有一个搀和的?搀和应该是把两者长入起来吧?局部符合脸色细节,彭胀符合执全局,但具体的复杂度优化幅度我不太信服。
口试官守望谜底:
Sparse Attention主要有三种典型类型:第一类是局部倨傲视力,基于语义局部性假定,每个元素仅脸色相邻k个位置的元素,复杂度降到O(kn),符合需要精确拿获局部语义细节的场景;第二类是彭胀倨傲视力,2026世界杯开运(中国)官方平台相同CV中的缺乏卷积,通过固定隔断k采样全局元素,能高效得回全局信息,但可能忽略局部细节;第三类是搀和寥落倨傲视力,由OpenAI建议,长入前两者的上风,同期脸色局部窗口和全局采样,是兼顾全局与局部信息的最优执行,符合大多量长序列处理场景。
第3题:Linear Attention是若何将复杂度从平日级降到线性级的?关键本领点是什么?
口试官发问:
Linear Attention能将复杂度从O(n²)降到线性级的中枢旨趣是什么?完了经由中需要惩办什么关键问题,有哪些惩办有盘算?
你的回话:
好像是改革了矩阵乘法的轨则?蓝本的倨傲视力是先算QK^T,江南app体育官网下载再乘V,Linear是先算K^T V,再乘Q?这么中间矩阵变小了?但好像因为softmax的存在弗成告成换,是以需要替换softmax?比如用elu+1之类的激活函数?具体的数学推导我不太熟。
口试官守望谜底:
Linear Attention的中枢旨趣是期骗矩阵乘法长入律,将原筹画轨则(QK^T)V改为Q(K^TV),原中间后果是n×n的选藏力矩阵,改为d×d的小矩阵(d为镶嵌维度),当d远小于n时,复杂度从O(n²)降到O(nd²),近似线性级。关键问题是原softmax必须依赖完好的QK^T矩阵,无法改革筹画轨则,因此需要替换softmax:一是用非负激活函数法,比如elu+1保证点积非负,替代softmax的归一化作用;二是softmax变换法,区分在序列维度和特征维度作念归一化,幸免全局筹画。
第4题:在骨子工程落地中,若何遴荐Sparse Attention和Linear Attention?
口试官发问:
当咱们需要处理长序列任务时,应该若何说明场景遴荐Sparse Attention也曾Linear Attention?各自的适用限度是什么?
你的回话:
如若序列相配长的话选Linear?因为它复杂度更低?如若需要脸色局部细节的话选Sparse?搀和的应该是两者王人兼顾?硬件资源不够的话选Linear,因为完了苟简?具体的限度比如序列长度若干切换我不太了了。
口试官守望谜底:
遴荐时需要长入场景需求、序列长度和硬件要求:第一江南体育(JNsports)官网app下载,若需要精确拿获局部语义细节,或序列长度中等,优先选Sparse Attention,尤其是搀和寥落类型,能兼顾全局与局部信息;第二,若处理超长序列(n巨大于d),或追求最低筹画复杂度,优先选Linear Attention,它的硬件友好性更好,完了更苟简;第三,若硬件资源受限且无需精确的局部选藏力,Linear Attention是更优遴荐;第四,若需要同期兼顾全局语义和局部细节,搀和寥落倨傲视力是最好均衡有盘算。